Notes On CUDA C++ Programming Guide
原文链接:Contents — CUDA C Programming Guide
1_Introduction
GPU 和 CPU 的区别
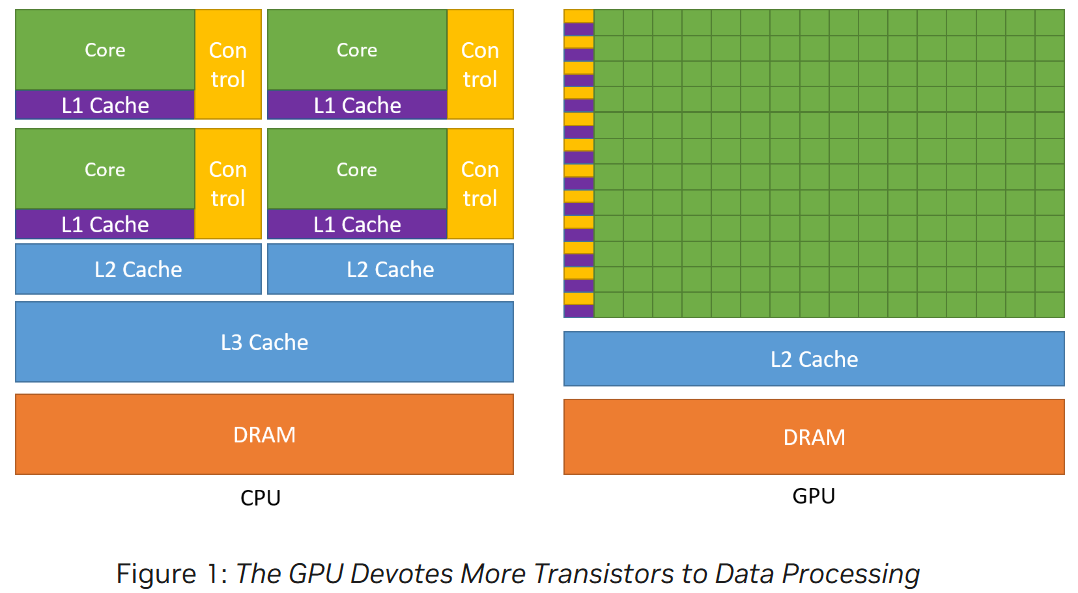
GPU 的计算应用

CUDA 并行编程模型是一种可拓展的编程模型,它的核心是三个关键的抽象:线程组;共享内存;同步屏障(barrier synchronization)。这三个抽象使得细粒度的数据并行和线程并行嵌套在了粗粒度的数据并行和任务并行中。
通过简单缩放多处理器和内存分区的数量,就可以实现可拓展的编程,而且只有 runtime system 需要知道物理多处理器数量
 ^5c4cc5
^5c4cc5
2_Programming Model
^ca8e6f
2.1_Kernels
kernel 通过 __global__ 定义,通过 <<<...>>> 指定配置。常规 C++函数只执行一次,CUDA C++的函数 Kernels 在 N 个不同的 CUDA 线程上执行 N 次。执行核的每个线程都有一个独一无二的线程 ID。
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
2.2_Thread Hierarchy
threadIdx 是一个三分量向量。对于一个三维尺寸为 $(Dx, Dy, Dz)$ 的 thread block, 线程索引为 $(x, y, z)$ 的线程 ID 为 $x+y\cdot Dx+z\cdot Dx \cdot Dy$。
#include <device_launch_parameters.h>
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
因为一个 block 上的所有线程要共享同一个 SM (streaming multiprocessor),所以在目前的 GPU 上,单个 thread block最多包含 1024 个线程。
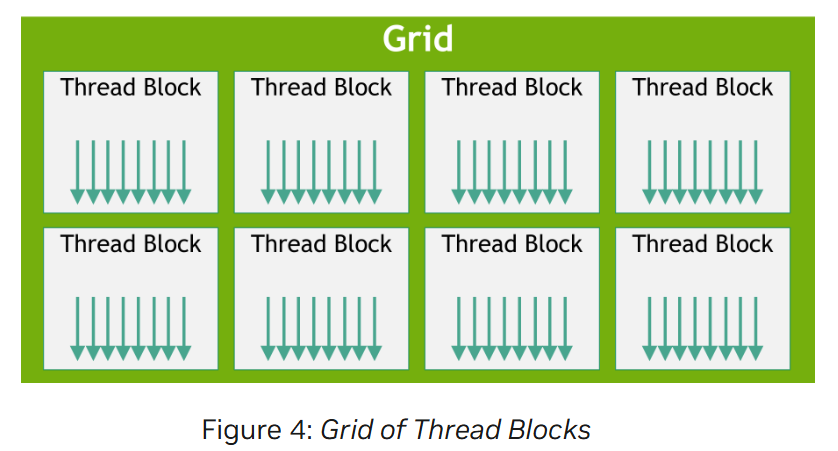
Blocks 同时也会被组织成一维、二维或者三维的线程块网格 (grid),并可以通过内置变量 blockIdx, blockDim 访问 kernel 中的唯一索引。
The number of threads per block and the number of blocks per grid specified in the <<<...>>> syntax can be of type int or dim3。
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
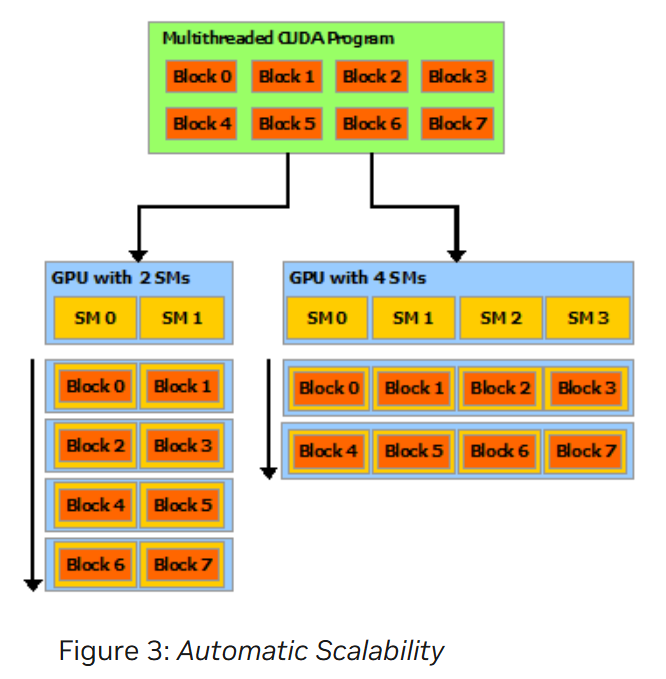
虽然线程块的尺寸可以任意选择,但通常设置为 $16\times 16$(256 threads)。线程块需要能够独立执行,这种独立性保证 thread block 可以以任何顺序(并行或者串行)在任何数量的 cores 上调度([[#^5c4cc5|Figure3_自动可扩展性]] ),从而使得程序能够随内核数量而拓展并行速度
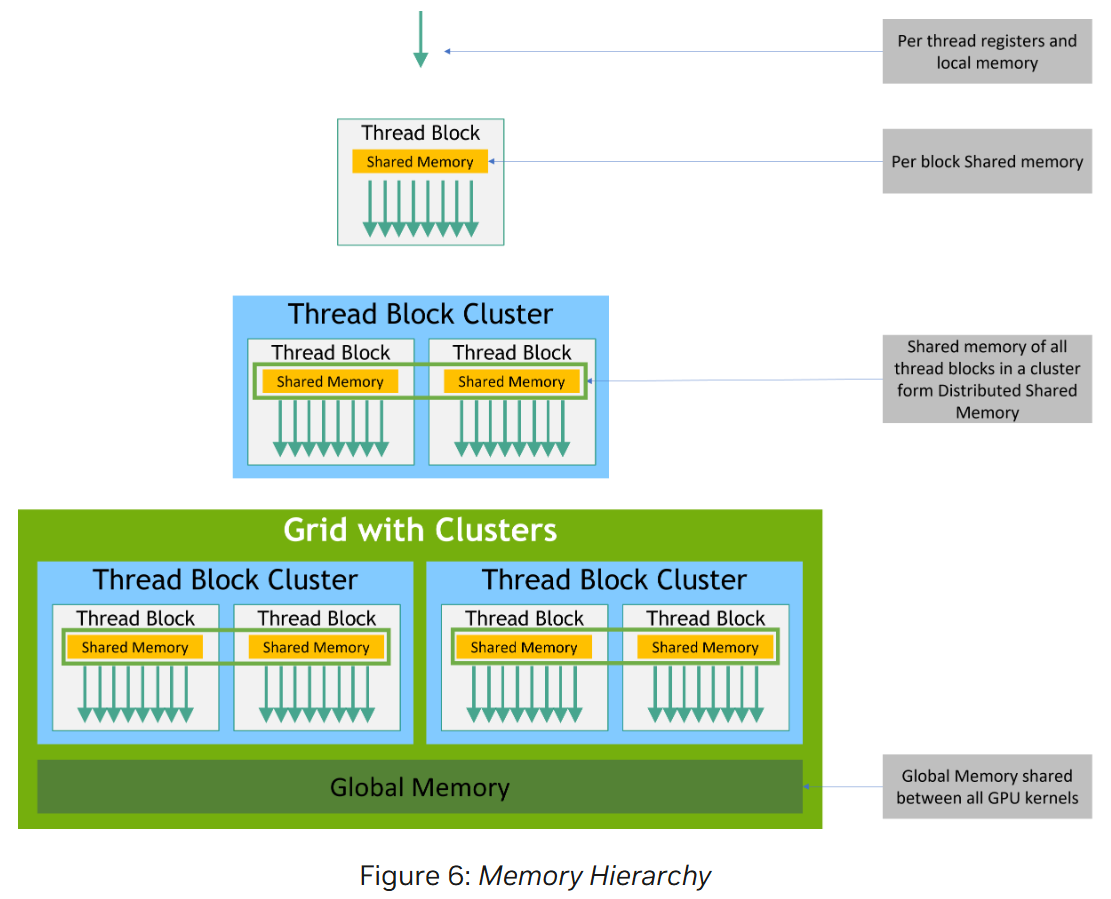
block 内的 threads 可以通过 shared memory 和 synchronize 来协调内存访问。内置函数 __syncthreads() 充当一个屏障,block 中的所有线程都必须等待其他线程执行到此处。
共享内存应该是靠近处理器核心的低延迟内存(很像 L1 cache),__syncthreads() 应该是轻量的。
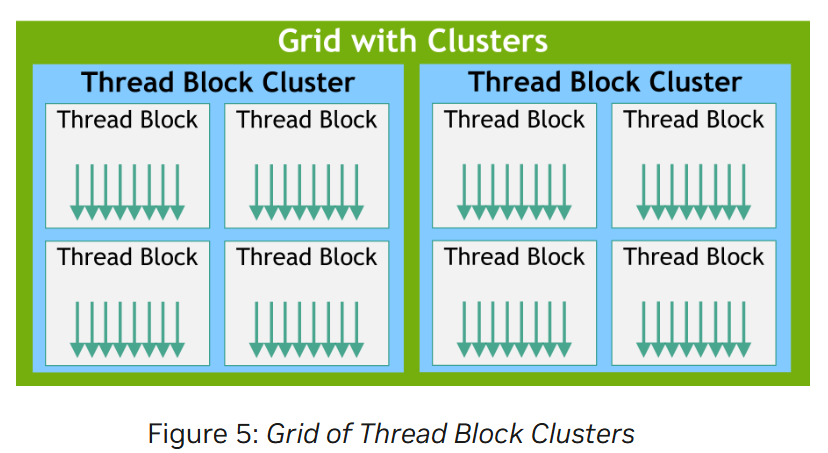
还有一种可选的层次结构叫 Thread Block Clusters。 #待办
2.3_Memory Hierarchy
CUDA 线程在执行过程中可能访问多种内存空间。此外还有两个只读内存空间可供所有线程访问:常量内存空间和纹理内存空间 (the constant and texture memory spaces)
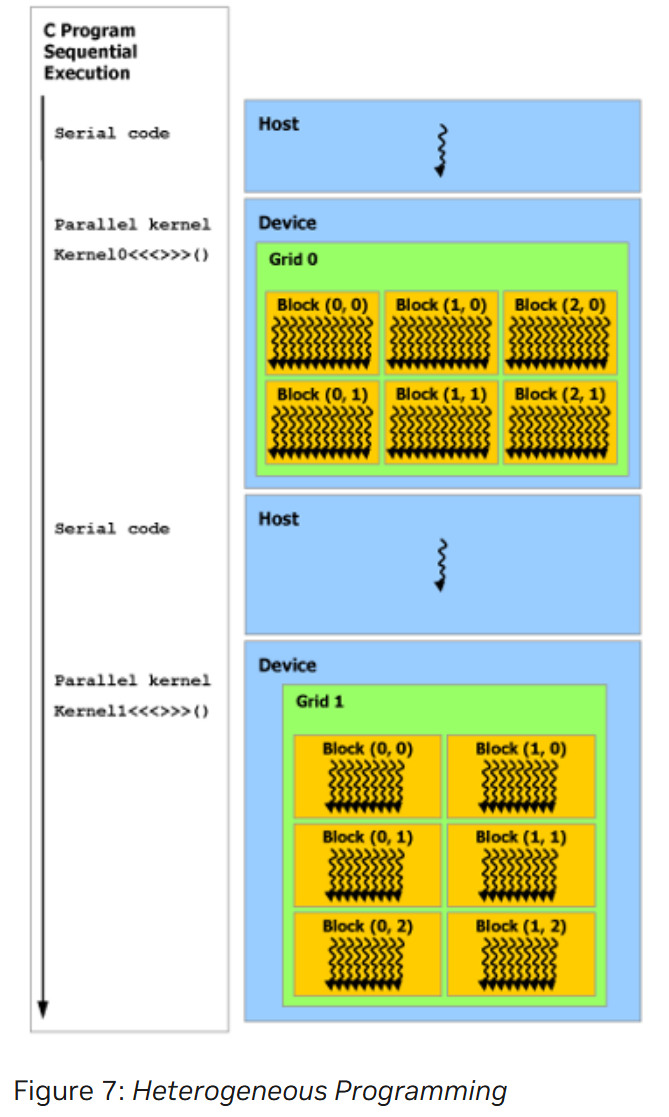
2.4_Heterogeneous Programming
CUDA 编程模型假设串行代码在主机 host 上执行,而并行代码(CUDA 线程)在物理上独立的设备 device 上执行,所以主机和设备分别维护自己的内存(主机内存和设备内存)。主机程序管理对设备内核可见的全局、常量和纹理内存空间,包括设备内存的分配和释放,以及主机和设备之间的数据交互。
Unified Memory 提供 managed memory 来桥接主机和设备内存空间。managed memory可以从系统中的所有 CPU 和 GPU 访问,作为具有公共地址空间的单个连贯内存映像。
2.5_Asynchronous SIMT Programming Model
在 CUDA 编程模型中,线程是进行计算或内存操作的最低抽象层级。
异步操作被定义为由 CUDA 线程发起并异步执行的操作,就像由另一个线程执行一样,发起异步操作的 CUDA 线程不需要在同步线程中。异步操作使用同步对象来同步操作的完成。
同步对象可以是 cuda::barrier or cuda::pipeline
2.6_Compute Capability
设备的计算能力由版本号表示,有时也称为“SM 版本”。具有相同主要修订号的设备具有相同的核心架构。
3_Programming Interface
CUDA C++由 C++语言的一组最小扩展和一个 runtime library 组成。核心语言拓展在 [[#^ca8e6f|2_Programming Model]] 中已经介绍了,任何包含这些拓展的源文件必须使用 nvcc 进行编译
runtime 提供在主机上执行的 C 和 C++函数,用于分配和释放设备内存、在主机内存和设备内存之间传输数据、管理具有多个设备的系统等。
3.1_Compilation with NVCC
待办
3.2_CUDA Runtime
runtime 在 cudart 库中实现
静态库:cudart.lib (windows) 或 libcudart.a (linux)
动态库:cudart.dll (windows) 或 libcudart.so (linux)
它的所有入口点都以 cuda 作为前缀
3.2.1_Initialization
- CUDA 12.0 之后:
- 调用
cudaInitDevice()andcudaSetDevice()会初始化运行时环境以及与指定设备关联的主上下文 (primary context)。 - 如果没有显式调用这些函数,运行时将默认使用
device 0,并在需要时自动进行初始化,以便处理其他运行时 API 请求。
- 调用
- 注意:
- 当你在 计时 runtime function 调用时,或者在解释第一次调用运行时时返回的错误代码时,需要考虑上述初始化行为。
- 原因是:初始化过程会引入额外的开销(例如,启动时间),而且在初始化之前,错误代码可能不同于初始化之后的错误代码。
- CUDA 12.0 之前
cudaSetDevice()不会初始化runtime。因此,开发者通常会使用cudaFree(0)这样的无操作调用来显式初始化运行时环境。- 这样做的目的是将运行时初始化与其他 API 活动(例如计时、错误处理)分开,以便更精确地控制和分析性能。
CUDA Runtime 会为系统中的每个 device 创建一个 CUDA context,并在所有主机线程之间共享。context 是 CUDA 中用于管理设备资源(如内存和内核配置)的结构,可以理解为每个设备的运行环境。